Ich bin auf der Suche nach einer Möglichkeit, Clustering separat auf Matrixzeilen und dann auf seinen Spalten durchzuführen, ordnen Sie die Daten in der Matrix neu, um das Clustering widerzuspiegeln und alles zusammenzufassen . Das Clusterproblem ist leicht lösbar, ebenso die Erzeugung des Dendrogramms (zum Beispiel in this blog oder in "Programming collective intelligence"). Wie ich die Daten neu anordne, bleibt jedoch unklar.Matrixelemente neu gruppieren, um das Spalten- und Zeilenclustering in Naiv Python widerzuspiegeln
Schließlich bin ich auf der Suche nach einer Möglichkeit zur Erstellung von Grafiken ähnlich wie die unten mit naiven Python (mit einer "Standard" -Bibliothek wie numpy, matplotlib usw., aber ohne using R oder andere externe Tools).
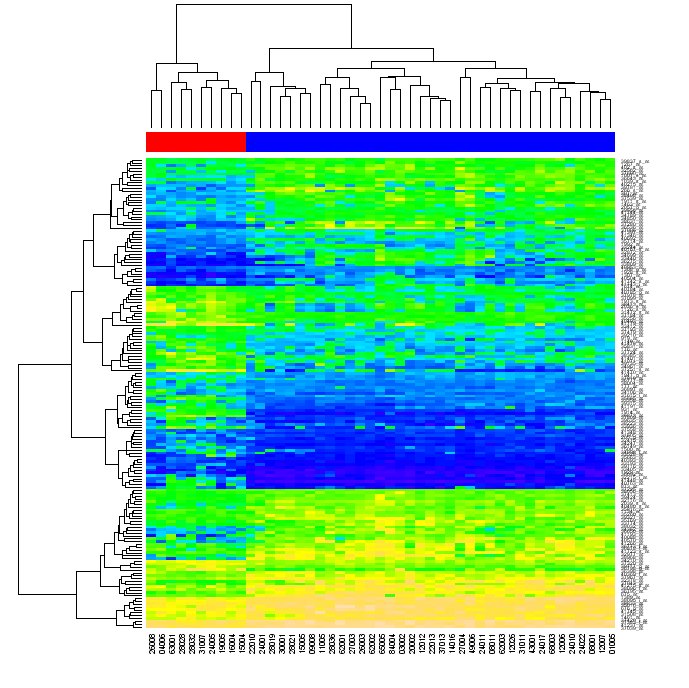
dendogram http://www2.warwick.ac.uk/fac/sci/moac/currentstudents/peter_cock/r/heatmap/no_scaling.png
{kind=link}
Clarifications
Ich wurde gefragt, was ich von Neuordnungs gemeint. Wenn Sie Daten in einer Matrix zunächst nach Matrixzeilen gruppieren, kann jede Matrixzelle anhand ihrer Spalten durch die Position in den beiden Dendrogrammen identifiziert werden. Wenn Sie die Zeilen und die Spalten der ursprünglichen Matrix so neu anordnen, dass die Elemente, die sich in den Dendrogrammen nahe beieinander befinden, einander in der Matrix nahe kommen und dann Heatmap generieren, kann das Clustering der Daten für den Betrachter sichtbar werden (wie in der Abbildung oben)
{kind=link}
Was meinst du mit Nachbestellung? Tausche n benachbarte Zeilen/Spalten mit einem anderen n? –
Sie möchten numpy/scipy verwenden, wenn Sie sicher mit Matrizen umgehen. Matplotlib ahmt auch Matlab gut nach. Hier ist ein Deal: Wenn Sie dies in Matlab tun können, können Sie es auch in scipy tun (trivial Syntax Unterschied, wenn vorhanden). –
Ooh, +1 für das schöne Bild ;-) –