7
dieser reguläre Ausdruck sollte mit einem HTML-Start-Tag übereinstimmen, denke ich.Bedeutung von ( /?) In Regex/ist ( w +) ([^>] *?) Eine Redundanz?
var results = html.match(/<(\/?)(\w+)([^>]*?)>/);
Ich sehe es sollte zuerst die < erfassen, aber dann bin ich verwirrt, was das Einfangen (\/?) erreicht. Bin ich richtig in Argumentation, dass die ([^>]*?)> sucht für jedes Zeichen außer >> = 0 mal? Wenn ja, warum ist die (\w+) Erfassung notwendig? Ist es nicht in den Zuständigkeitsbereich des fallen [^>]*?
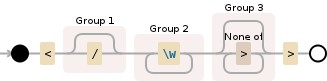
es findet End-Tags, die Sie kennen anstelle von ... das \ w erfasst den Tag-Namen zu einem Parameter anstelle Ersatz es mit dem Attribut-Abschnitt für eine Übereinstimmung zu bündeln, die Sie nicht benötigen es, aber wenn die regexp helfen, wenn in ein replace() recycelt wird ... – dandavis