1
aus einem String wieSpiel erste Klammer mit Python
70849 mozilla/5.0(linux;u;android4.2.1;zh-cn)applewebkit/534.30(khtml,likegecko)version/4.0mobilesafari/534.30
Ich mag linux;u;android4.2.1;zh-cn den ersten geklammerten Inhalt erhalten.
Mein Code sieht wie folgt aus:
s=r'70849 mozilla/5.0(linux;u;android4.2.1;zh-cn)applewebkit/534.30(khtml,likegecko)version/4.0mobilesafari/534.30'
re.search("(\d+)\s.+\((\S+)\)", s).group(2)
aber das Ergebnis ist die letzte Klammer Inhalt khtml,likegecko.
Wie löst man das?
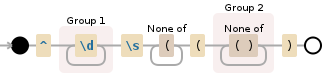
Es funktioniert! Mein '(\ d +) \ s \ (([^()] *) \ s \ (([^()] *) \) 'fehlgeschlagen liefert null @Wiktor –
Bitte beachten Sie meine Erklärungen: Ihr Muster enthielt ein gieriges Punkt-Matching-Muster, das die ersten Klammern übersprang, um zu den letzten zu gelangen statt dessen. –
Ich weiß, gierigen Auswirkungen! '(\ d +) \ s (([^()] *))' Dies gab nicht die Nummer, verwenden Sie die Gruppe (1). Aber Ihre funktioniert –