0
Ich versuche, ein Modell von this image zu machen. Hier ist der entsprechende Code:Bild als Eingabe und Ausgabe in Keras
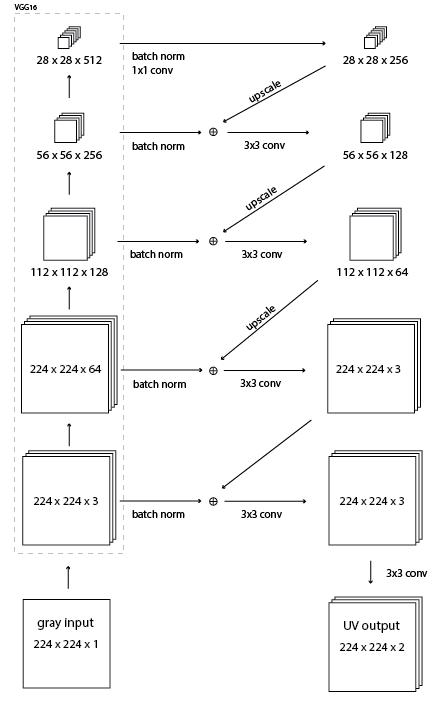{kind=link}
base_model = VGG16(weights='imagenet')
conv4_3, conv3_3, conv2_2, conv1_2 = base_model.get_layer('block4_conv3').output,
base_model.get_layer('block3_conv3').output,
base_model.get_layer('block2_conv2').output,
base_model.get_layer('block1_conv2').output
# Use the output of the layers of VGG16 on x in the model
conv1 = Convolution2D(256, 1, 1, border_mode='same')(BatchNormalization()(conv4_3))
conv1_scaled = resize(conv1, 56)
.
.
.
conv5 = Convolution2D(3, 3, 3, border_mode='same')(merge([ip_img, conv4], mode='sum'))
op = Convolution2D(2, 3, 3, border_mode='same')(conv5)
for layer in base_model.layers:
layer.trainable = False
model = Model(input=base_model.input, output=op)
model.compile(optimizer='sgd', loss=custom_loss_fn)
Ich habe eine Reihe von farbigen Bildern in einem Verzeichnis. Das Eingabebild sollte die Graustufe eines dreifach gestapelten Bildes (224x224x3) sein und die op sollte die UV-Ebenen des Bildes (224x224x2) sein, die ich der Graustufe hinzufügen kann (224x224x1), um das YUV-Bild zu erhalten. Die benutzerdefinierte Verlustfunktion arbeitet mit dem UV des Originalbildes und dem UV der Vorhersage.
Wie trainiere ich es?