Ich bin mir nicht sicher, mit welcher Art von Daten Sie es zu tun haben, aber hier ist eine Methode, die ich für die Verarbeitung von Sprachdaten verwendet habe, die Ihnen helfen könnte, lokale Maxima zu finden. Es verwendet drei Funktionen aus der Signal Processing Toolbox: HILBERT, BUTTER und FILTFILT.
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
Sie würden dann Ihre Maxima Befund auf smoothData zuführen. Die Verwendung von HILBERT erzeugt zuerst eine positive Hüllkurve auf den Daten, dann verwendet FILTFILT die Filterkoeffizienten von BUTTER, um die Datenhüllkurve tief zu filtern.
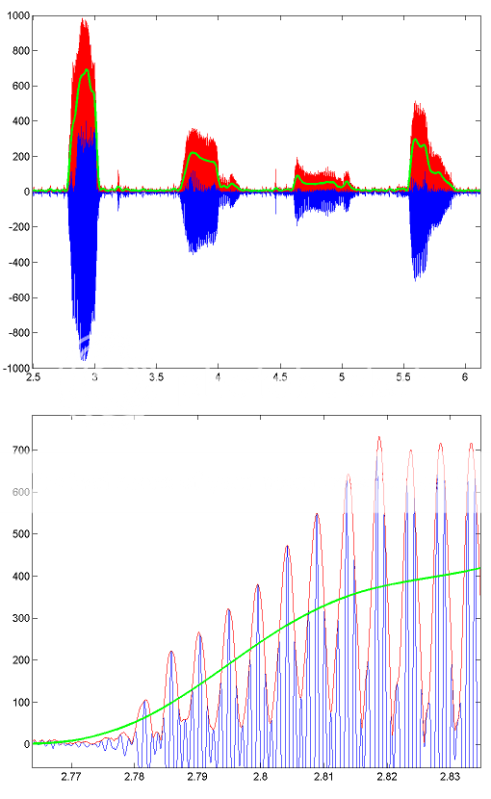
Für ein Beispiel, wie diese Verarbeitung funktioniert, hier sind einige Bilder, die die Ergebnisse für ein Segment der aufgezeichneten Sprache zeigen. Die blaue Linie ist das ursprüngliche Sprachsignal, die rote Linie ist die Hüllkurve (erhalten mit HILBERT) und die grüne Linie ist das Tiefpass-Ergebnis. Die untere Abbildung ist eine vergrößerte Version der ersten.
etwas zufällig eventuell helfen:
Dies ist eine zufällige Idee war ich zuerst hatte ... Sie könnten versuchen, den Prozess zu wiederholen, indem sie die maximas der maximas finden:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
In Abhängigkeit vom Signal-Rausch-Verhältnis wäre es jedoch unklar, wie oft es wiederholt werden müsste, um die lokalen Maxima zu erhalten, an denen Sie interessiert sind. Es ist nur ein Rando m nicht filternde Option zu versuchen. =)
MAXIMA FINDING:
Gerade falls Sie neugierig ist, ein weiterer einzeiligen Maxima-Suchalgorithmus, die ich (zusätzlich zu dem einen gesehen haben Sie aufgelistet) ist:
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
Da Sie Ihre Frage aktualisiert haben, um zu sagen, dass Sie mit Bildern arbeiten, ist die obige Maxima-Befund-Gleichung (die für Vektoren spezifischer ist) möglicherweise nicht ideal für Sie. Ich würde vorschlagen, die Bildverarbeitungs-Toolbox in MATLAB zu betrachten, wenn Sie Zugriff darauf haben. Es kann einige Operationen geben, die dir helfen. Geben Sie einfach "Hilfe Bilder" in MATLAB ein, um die Funktionsliste auszuprobieren. – gnovice