Ich habe ein Problem mit der Regex-Syntax in Mysql, wenn es darum geht, whitespaces in Strings zu entsprechen.MySQL Matching Leerzeichen in Regex
Ich habe eine Datenbank von Postleitzahlen im Format:
1111 AA CITYNAME oder 1111 CITYNAME.
Daraus mag ich die zipcode und den Städtenamen extrahieren, habe ich den folgenden Code:
DROP FUNCTION IF EXISTS GET_POSTALCODE;
CREATE FUNCTION GET_POSTALCODE(input VARCHAR(255))
RETURNS VARCHAR(255)
BEGIN
DECLARE output VARCHAR(255) DEFAULT '';
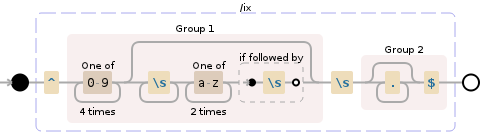
IF input LIKE '^[1-9][0-9]{3}[[:blank:]][A-Z]{2}[[:blank:]]%'
THEN
SET output = SUBSTRING(input, 1, 7);
ELSE
SET output = SUBSTRING(input, 1, 4);
END IF;
RETURN output;
END
Ich würde das Ergebnis für eine Eingabezeichenfolge von 9741 NE Groningen erwartet in 9741 NE und Groningen aufgeteilt werden.
Aber stattdessen bekomme ich 9741 und NE Groningen.
Ich habe alle möglichen Dinge versucht, die Whitespace, die ich denke, ist das Problem. Ich habe versucht:
[[:blank:]][:blank:][[:space:]][:space:]- und die
\sMethode
[:space:] Sollten alle Leerzeichen übereinstimmen, aber noch einmal, das gleiche Resultat.
Nichts, was ich versuche, scheint zu funktionieren, könnten Sie mir vielleicht in die richtige Richtung zeigen?
Vielen Dank!
dies "AA" von "1111 AA CITYNAME" immer zwei Zeichen lang oder kann es mehr oder weniger sein? – davidbucka
Die Buchstaben sind immer 2, nicht mehr, aber in einigen Fällen werden die 2 Buchstaben nicht geliefert, und den 4 Zahlen folgt sofort ein Leerzeichen und der cityName – MalumAtire832
okay - ich weiß jetzt nicht weiter, aber vielleicht wird dir das zeigen in eine bessere Richtung: \ s + (? = \ S * + $) gibt dir den letzten Whitespace, aber ich bekomme nicht, wie ich danach und danach werden soll. – davidbucka