2
zurückzukehren Wie einen generischen regulären Ausdruck zu schreiben, das wird
1) Capture-String nach dem ersten _ und vor dem zweiten _ als Gruppe 1
2) Capture-String nach dem letzten _ als Gruppe 2Regulärer Ausdruck Zeichenfolge aus dem Dateinamen
Beispiel
ASIA_JAP_TOKYO_201109
OUTPUT Würde
group 1 - JAP
group 2 - 201109
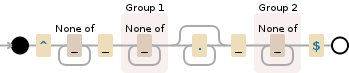
'/^[^_]+_([^_]+).*_([^ _] +) $/' –